

이전 포스팅에서 도커 이미지가 무엇인지, 컨테이너가 무엇인지를 알아 보았다. 이번에는 좀 더 실용적인 방법에 대한 고민과 함께 퍼시스턴트 데이터와 볼륨에 대해서 연결해서 설명해 보려고 한다.
도커를 사용해 시스템을 구성한다는 것은 대부분 자신이 만든 어플리케이션의 컨테이너는 물론이고 도커 허브에 공개된 어플리케이션이나 미들웨어 이미지로 만든 컨테이너가 서로 협력하는 스택을 구축하는 것이다. 실제 운영에서는 어플리케이션을 컨테이너 안에 어떻게 배치하는지가 매우 중요하다. 컨테이너 하나가 어느 정도의 책임을 맡는 것이 적정 수준일까? 단일 컨테이너의 시스템 내 비중을 어떻게 결정하는지 알아보자.
정기적으로 어떤 작업을 실행해야 하는 컨테이너가 있다고 가정하자. 스케줄러는 직접 갖춘 어플리케이션도 있겠지만, 외부에 의존하는 경우가 많으므로 어플리케이션은 스케줄러 기능을 가지고 있지 않다고 생각하자. 만약 여기서 <컨테이너 1개 = 프로세스 1개>의 방식을 택하게 된다면 cron이 1개의 컨테이너고 실행되는 작업이 또 1개의 컨테이너를 차지하는 형태가 되어야 한다. 실제로 구성하려면 다음과 같이 생각할 수 있다.
-
작업 컨테이너 쪽에 작업을 실행하는 트리거 역할을 할 API를 갖추고, cron 컨테이너가 컨테이너 간 통신을 통해 이 API를 호출하는 구조.
-
cron 컨테이너에 도커를 구축하고 다시 그 위에서 작업 컨테이너를 실행하는 구조
이와 같은 방법은 상당히 복잡하다. 이런 방법 대신에 작업을 수행하는 프로세스와 스케줄러 기능을 하는 프로세스가 하나의 컨테이너 안에서 실행될 수 있게 만들면 훨씬 깔끔하게 작업을 할 수 있다. <컨테이너 1개 = 프로세스 1개>의 방식을 항상 고집할 필요는 없다.
도커 공식 홈페이지에는 Dockerfile에 대해서 다음과 같은 문구가 적혀져 있다.
Each container should have only one concern
컨테이너는 하나의 관심사에만 집중해야 한다.
즉, 컨테이너 하나가 한 가지 역할이나 문제 영역(도메인)에만 집중해야 한다는 것이다. 예를 들어 전통적인 웹 어플리케이션에서, 컨테이너를 사용하지 않는 스택은 리버스 프록시, 어플리케이션, 데이터 스토어가 서로 독립적으로 자기 역할을 수행하며 전체 시스템을 구성한다. 이런 분리 구조를 컨테이너로 그대로 바꾸어 주어도 어색한 점은 없다. 처리할 트래픽이 많고 컨테이너를 사용한다면, 각각을 컨테이너로 구성해 이를 복제하는 방식으로 스케일링이 가능할 것이다.
이전 포스팅에서 설명한 것처럼 도커의 장점 중 하나는 이식성(portability)에 있다. 도커를 사용하면 어플리케이션과 인프라를 컨테이너라는 단위로 분리할 수 있으며, 도커가 설치된 환경이라면 어떤 호스트 운영체제와 플랫폼, 온프레미스 및 클라우드 환경에서도 그대로 동작한다. 하지만 도커의 이식성은 완벽하지만은 않다.
호스트형 가상화 기술처럼 하드웨어를 연산으로 에뮬레이션하는 기술과 달리, 도커에서 사용되는 컨테이너형 가상화 기술은 호스트 운영체제와 커널 리소스를 공유한다. 이는 도커 컨테이너를 실행하려면 호스트가 특정 CPU 아키텍처 혹은 운영체제를 사용해야 한다는 의미이다. 예를 들면 라즈베리 파이 같은 ARM 계열의 armv71 아키텍처를 채용한 플랫폼에서 인텔의 x86_64 아키텍처에서 빌드한 도커 컨테이너를 실행할 수는 없다.
이 외에도 어플리케이션이 어떤 라이브러리를 사용하느냐에 따라 이식성을 해치는 경우가 있다. 네이티브 라이브러리를 동적 링크에 사용하는 경우가 그렇다. 정적 링크는 어플리케이션에 사용된 라이브러리를 내부에 포함하는 형태이므로 어플리케이션의 크기가 비대해지는 경향이 있지만 이식성을 뛰어나다. 반면 동적 링크는 어플리케이션을 실행할 때 라이브러리가 링크되므로 어플리케이션의 크기는 작아지지만 어플리케이션을 실행할 호스트에서 라이브러리를 갖춰야 한다는 문제가 생긴다.
도커에서는 이런 문제에 대한 해결책으로 multi-stage builds라는 메커니즘을 제시했다. 이 방법은 컨테이너를 빌드용과 실행용으로 분리해서 사용하는 방법으로, 실행용 컨테이너를 빌드에 사용하면서 빌드에 쓰이는 도구로 인해 컨테이너가 지나치게 커지는 것을 방지한다. 이 방법 역시 이식성을 해결하기에 완벽한 방법은 아니어서, 지속적으로 이에 대해서는 고민을 해야 한다.
각 컨테이너와 호스트 사이에서 퍼시스턴스 데이터(persistent data)를 주고받기 위해 사용되는 것이 데이터 볼륨(data volume)이다. 컨테이너를 사용해서 상태를 갖는 어플리케이션을 운영하려면 새로운 버전의 컨테이너가 배포되어도 이전 버전의 컨테이너에서 사용하던 파일 및 디렉터리를 그대로 사용할 수 있어야 한다.
데이터 볼륨은 도커 컨테이너 안의 디렉터리를 디스크에 퍼시스턴스 데이터로 남기기 위한 메커니즘으로, 호스트와 컨테이너 사이의 디렉터리 공유 및 재사용 기능을 제공한다. 이미지를 수정하고 새로 컨테이너를 생성해도 같은 데이터 볼륨을 계속 사용할 수 있다. 데이터 볼륨은 컨테이너를 파기해도 디스크에 그대로 남으므로 컨테이너로 상태를 갖는 어플리케이션을 실행하는데 적합하다.
데이터 볼륨을 생성하려면 다음과 같이 docker container run 명령에 -v 옵션을 사용하면 된다.
$ docker container run [options] -v 호스트_디렉터리:컨테이너_디렉터리 레포지토리명[:태그] [명령] [명령인자]
이 방법을 사용하면 컨테이너 안의 설정 파일을 쉽게 수정할 수 있지만, 호스트 안의 특정 경로에 의존성이 생기기 때문에 호스트 쪽 데이터 볼륨을 잘못 다루면 어플리케이션에 부정적인 영향을 미칠 수 있다. 이 때문에 이식성 면에서는 아직 개선의 여지가 필요하다.
컨테이너의 데이터 퍼시스턴스 기법으로 추천되는 것이 데이터 볼륨 컨테이너이다.
앞서 설명한 데이터 볼륨은 컨테이너와 호스트 사이의 디렉터리를 공유하는 것이었으나, 데이터 볼륨 컨테이너는 컨테이너 간에 디렉터리를 공유한다.
데이터 볼륨 컨테이너는 이름 그대로 데이터를 저장하는 것만 목적으로 하는 컨테이너이다. 디스크에 저장된 컨테이너가 갖는 퍼시스턴스 데이터를 볼륨으로 만들어 다른 컨테이너에 공유하는 컨테이너가 데이터 볼륨 컨테이너이다.
호스트-컨테이너 데이터 볼륨은 호스트 쪽 특정 디렉터리에 의존성을 갖는다. 데이터 볼륨 컨테이너의 볼륨은 도커에서 관리하는 영역인 호스트 머신의 /var/lib/docker/volumes/ 아래에 위치한다. 데이터 볼륨 컨테이너 방식은 도커가 관리하는 디렉터리에만 영향을 미친다. 호스트-컨테이너 데이터 볼륨과 비교하면 호스트 머신이 컨테이너에 미치는 영향을 최소한으로 억제한다. 또 데이터 볼륨 컨테이너가 직접 볼륨을 다뤄주므로 볼륨을 필요로 하는 컨테이너가 사용할 호스트 디렉터리를 알 필요가 없고, 디렉터리를 제공하는 데이터 볼륨 컨테이너만 지정하면 된다.

데이터 볼륨이 데이터 볼륨 컨테이너 안에 캡슐화 되므로 호스트에 대해 아는 것이 없어도 데이터 볼륨을 사용할 수 있다. 또한 컨테이너 안에 든 어플리케이션과 데이터의 결합이 더 느슨하므로 어플리케이션 컨테이너와 데이터 볼륨을 교체할 수도 있다.
예제를 하나 가지고 설명을 하려고 한다. 데이터 볼륨에 MySQL 데이터를 저장하는 예제이다.
데이터 볼륨 컨테이너 역할을 할 이미지를 다음과 같이 Dockerfile로 생성한다.
이미지를 빌드하고
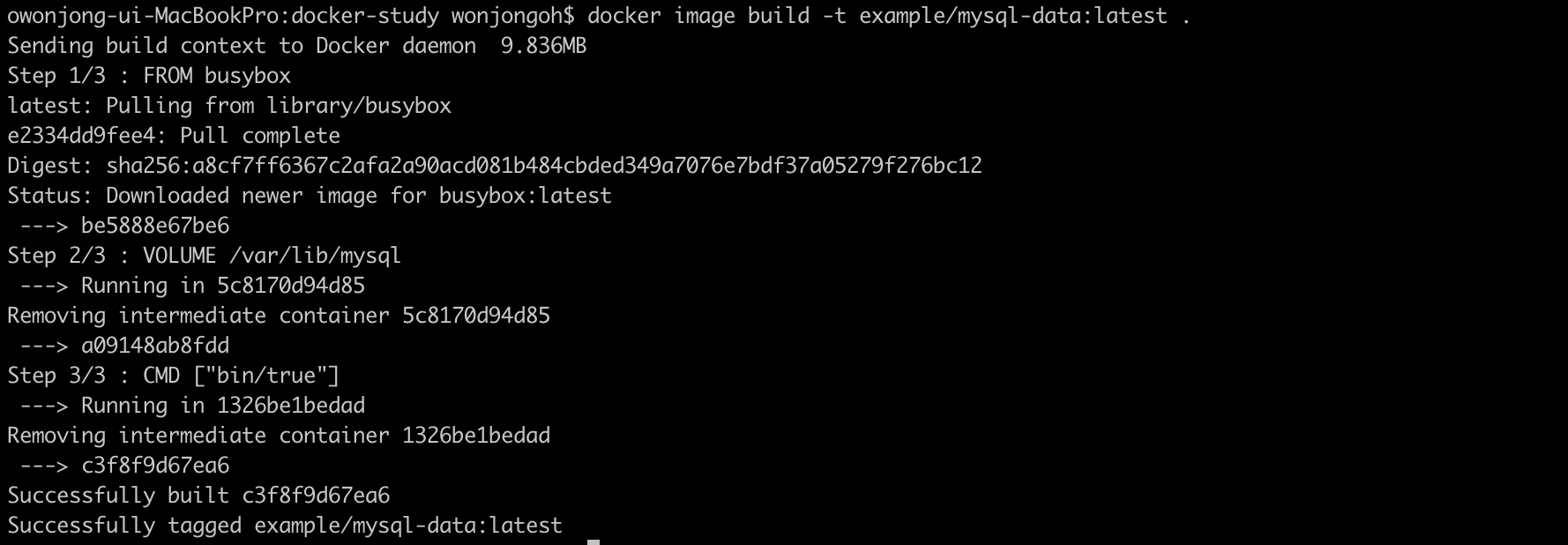
데이터 볼륨 컨테이너를 실행한다.

MySQL을 실행시킬 컨테이너를 실행한다. 몇 가지 환경변수를 설정했다.

실행중인 MySQL 컨테이너에 root 계정으로 로그인 한다. 패스워드는 빈 문자열이다. 그리고 초기 데이터를 넣고 잘 들어갔는지 확인해 보았다.

컨테이너를 정지하고 (만들 때 --rm 옵션을 붙여서 실행했으므로 정지와 함께 삭제됨)

다시 새로운 컨테이너를 실행한다.

확인해 본 결과 데이터가 잘 남아있음을 알 수 있었다.

이렇게 어플리케이션 컨테이너와 데이터 볼륨 컨테이너를 분리하면 쉽게 데이터와 컨테이너를 교체할 수 있다.
참고자료
- <도커/쿠버네티스를 활용한 컨테이너 개발 실전 입문> 야마다 아키노리 저
- <Docker Mastery with Kubernetes and Swarm> Udemy course
'Prog. Langs & Tools > Docker' 카테고리의 다른 글
| Docker #6. 스웜을 사용한 실전 어플리케이션 개발 - Part1 (0) | 2021.05.29 |
|---|---|
| Docker #5. 여러 대의 도커 호스트를 다뤄보기 (0) | 2021.01.04 |
| Docker #4. Docker Compose를 실습해 보자! (0) | 2020.05.01 |
| Docker #2. 도커 이미지와 컨테이너(images and containers) (0) | 2020.04.13 |
| Docker #1. 도커(Docker)란 무엇인가? (0) | 2020.04.07 |