

동시성 프로그래밍에서 여러 프로세스 사이의 협조가 필요한데, 프로세스 사이에 타이밍 동기화, 데이터 업데이트 등을 협조적으로 수행하는 처리를 동기 처리(synchronous processing)라 부른다.
3.1 레이스 컨디션
레이스 컨디션(race condition)은 경합 상태라고 불리며, 여러 프로세스가 동시에 공유하는 자원에 접근함에 따라 일어나는 예상치 않은 이상이나 상태를 의미한다. 동시성 프로그래밍에서는 이 레이스 컨디션을 일으키지 않고 올바르게 프로그래밍을 하는 것이 중요한 문제이다.
예를 들어 공유 메모리 상에 있는 변수를 여러 프로세스가 증가시킨다고 가정하자. 이 때 메모리에 읽기와 쓰기를 동시에 수행할 수는 없고, 각각 다른 타이밍에 수행한다고 가정한다. 아래 그림은 프로세스 A, B가 공유 변수 v를 증가시키는 예시이다.

읽고 쓰기를 4번 하였지만 결과가 3이 나왔다. 이와 같이 동시성 프로그래밍에서 예기치 못한 결함에 빠지는 상태를 레이스 컨디션이라고 한다. 이렇게 레이스 컨디션을 일으키는 부분을 크리티컬 섹션(critical section)이라고 하며, 크리티컬 섹션을 보호하기 위해서는 동기 처리 구조를 이용한다.
3.2 아토믹 처리
아토믹 처리(atomic operation)란 불가분 조작 처리라 불리며 더 이상 나눌 수 없는 처리 단위를 의미한다. 엄밀하게 생각하면, CPU의 add나 mul 같은 명령도 아토믹 처리로 생각할 수 있지만 일반적으로 아토믹 처리는 여러 번의 메모리 접근이 필요한 조작이 조합된 처리를 말하며 덧셈이나 곱셈 등 단순한 명령을 의미하지는 않는다. 아토믹 하다의 정의는 해당 처리의 도중 상태는 시스템적으로 관측할 수 없으며, 만약 처리가 실패하면 처리 전 상태로 완전 복원되는 성질이다.
3.2.1 Compare and Swap
Compare and Swap(CAS)은 동기 처리 기능의 하나인 세마포어(semaphore), 락 프리(lock-free), 웨이트 프리(wait-free)한 데이터 구조를 구현하기 위해 이용되는 처리다. 아래 예제 코드는 CAS의 의미를 나타낸 예제 코드이다.
bool compare_and_swap(uint64_t *p, uint64_t val, uint64_t newval)
{
if (*p != val) { // *p의 값이 val과 다르면 false를 반환한다.
return false;
}
*p = newval; // *p의 값이 val과 같으면 *p에 newval을 대입하고 true를 반환한다.
return true;
}일반적으로 이 프로그램은 아토믹하지 않다. 실제로 2행의 _p ≠ val은 5행의 *p = newval과 별도로 실행된다. C 코드에서 나타난 처리는 일반적으로 어셈블리 코드 레벨에서 여러 조작을 조합해서 구현한다. 하지만 gcc나 clang 같은 C 컴파일러에서는 이와 같은 조작을 아토믹으로 처리하기 위한 내장함수인 ___sync_*bool_compare_and_swap을 제공한다.
bool compare_and_swap(unit64_t *p, uint64_t val, uint64_t newval)
{
return __sync_bool_compare_and_swap(p, val, newval);
}이 코드는 다음 어셈블리 코드로 변환된다.
movq %rsi, %rax; %rax = %rsi, 두 번째 인수를 의미하는 rsi 레지스티의 값을 rax 레지스티로 복사한다.
xorl %ecx, %ecx; %ecx = 0, ecx 레지스터의 값을 0으로 초기화한다.
lock cmpxchgq %rdx, (%rdi); CAS
sete %cl; %cl = ZF flag, sete 명령은 Set Byte on Condition 명령이라 불리는 명령의 하나이며, ZF 클래스의 값을 cl 레지스터에 저장한다.
movl %ecx, %eax; %eax = %ecx
retq;코드 주석 CAS에 대한 추가적인 설명을 하면 cmpxchgq 명령을 이용해 아토믹하게 비교 및 교환한다. lock을 지정한 경우 지정된 명령 중의 메모리 접근은 배타적으로 수행됨을 보증한다. 더 구체적으로 이야기 하면 명령 안에 지정된 메모리에 해당하는 CPU 캐시 라인의 소유권이 배타적인 것을 보증한다. 즉, CPU가 여럿인 경우에도 lock에 설정된 메모리에 접근할 수 있는 CPU는 동시에 하나뿐이다.
cmpxchgq 명령은 다음 코드와 그 의미가 같다.
if (%rax == (%rdi)) {
(%rdi) = %rdx
ZF = 1
} else {
%rax = (%rdi)
ZF = 0
}즉, cmpxchgq %rdx, (%rdi)에서는 먼저 rax 레지스터의 값과 첫 번째 인수를 나타내는 rdi 레지스터가 가리키는 메모리상의 값을 비교하여, 값이 같으면 rdi 레지스터가 가리키는 메모리상에 네 번째 인수를 나타내는 rdx의 값을 대입하고 ZF 플래그의 값을 1로 설정한다. 그렇지 않을 때는 rdi 레지스터가 가리키는 메모리상의 값을 rax 레지스터에 설정하고 ZF 플래그의 값을 0으로 설정한다.
3.2.2 Test and Set
아래 코드는 Test And Set(TAS)이라는 조작을 수행한다.
bool test_and_set(bool *p) {
if (*p) {
return true;
} else {
*p = true;
return false;
}
}이 함수는 입력된 포인터 p가 가리키는 값이 true이면 true를 그대로 반환하고, false면 p가 가리키는 메모리의 값을 true로 설정하고 false를 반환한다. TAS도 CAS와 마찬가지로 아토믹 처리의 하나이며, 값의 비교와 대입이 아토믹하게 실행이 되며 스핀락 등을 구현하기 위해 이용된다.
이 코드를 그대로 컴파일해도 아토믹하게 실행되지 않지만 CAS와 마찬가지로 gcc나 clang 등의 C 컴파일러에서는 TAS용 내장 함수인 __sync_lock_test_and_set을 제공한다. 하지만 이 함수의 작동은 test_and_set 함수(TAS 함수)와는 다르며, 그 의미는 다음 코드와 같다.
type __sync_lock_test_and_set(type *p, type val) {
type tmp = *p;
*p = val;
return tmp;
}이 함수는 포인터 p와 값 val을 인수로 받고, val을 포인터 p가 가리키는 값에 대입하고, p가 가리키던 이전 값을 반환한다.
다음 코드는 내장 함수를 이용해 아토믹하게 작동하는 TAS 함수다.
bool test_and_set(volatile bool *p) {
return __sync_lock_test_and_set(p, 1);
}여기에서는 앞서 설명한 것처럼 두 번째 인수에 상수 1을 전달한다. 이 코드는 다음 어셈블리 코드와 같이 컴파일된다.
movb $1, %al ; %al = 1
xchgb %al, (%rdi) ; TAS, xchgb 명령으로 al 레지스터의 값과 첫 번째 인수를 의미하는 rdi 레지스터가 가리키는 메모리의 값을 교환한다.
andb $1, %al ; %al = %al & 1, al 레지스터의 하위 1비트의 값이 추출된다.
retq__sync_lock_test_and_set 함수에서 설정한 플래그는 __sync_lock_release를 이용해 해제 할 수 있으며, 다음과 같이 매우 단순한 코드로 구현할 수 있다.
void tas_release(volatile book *p) {
return __sync_lock_release(p);
}3.2.3 Load-Link/Store-Conditional
x86-64나 그 기반이 되는 x86 등의 CPU 아키텍처에서는 lock 명령 접두사를 사용해 메모리에 읽고 쓰기를 배타적으로 수행하도록 지정했다. 한편 ARM, RISE-V, POWER, MIPS 등의 CPU에서는 Load-Link/Store-Conditional(LL/SC) 명령을 이용해 아토믹 처리를 구현한다.
LL 명령은 메모리 읽기를 수행하는 명령이지만 읽을 때 메모리를 배타적으로 읽도록 지정한다. SC 명령은 메모리 쓰기를 수행하는 명령이며, LL 명령으로 지정한 메모리로의 쓰기는 다를 CPU가 수행하지 않는 경우에만 쓰기가 성공한다.

먼저 프로세스 A가 LL 명령을 이용해 공유 변수 v의 값을 읽는다. 이어서 다른 프로세스가 B가 공유 변수 v에서 값을 읽고, 그 후 어떤 값을 써넣는다. 다음으로 프로세스 A가 SC 명령을 이용해 값을 써넣지만 프로세스 A의 LL 명령과 SC 명령 사이에 공유 변수 v로의 쓰기가 발생하므로 이 쓰기는 실패한다. 쓰기가 실패한 경우에는 다시 한 번 읽기와 쓰기를 수행함으로써 실질적으로 아토믹하게 증가시킬 수 있다.
다음 코드는 AArch64 어셈블리를 이용해 TAS 함수를 구현한 예다.
mov w8, #1 ; w8 = 1
.LBBO_1:
ldaxrb w9, [x0] ; w9 = [w0], 첫 번째 인수를 나타내는 x0 레지스터가 가리키는 메모리의 값을 w9 레지스터에 저장한다.
stlxrb w10, w8, [x0] ; [x0] = w8, w8 레지스터의 값을 x0 레지스터가 가리키는 메모리에 써 넣는다.
cbnz w10, .LBB0_1. ; if w10 != 0 then goto .LBB0_1, w10 레지스터의 값이 0이 아니면 3행부터 다시 처리를 실행하고, 그렇지 않으면 처리를 진행한다.
and w0, w9, #1 ; w0 = w9 & 1
retLL/SC 명령을 사용한 간단한 예를 다음 코드에 나타냈다. 이 코드는 아토믹하게 값을 증가시키는 예이며, 공유 변수로의 주소는 x0 레지스터에 저장되어 있다고 가정한다.
.LBB0_0:
ldaxr w8, [x0] ; x8 = [x0], x0 레지스터가 가리키는 메모리에서 값을 읽어 w8 레지스터에 저장한다
add w8, w8, #1 ; w8 = w8 + 1, w8 레지스터의 값을 증가
stlxr w9, w8, [x0] ; [x0] = w8, w8 레지스터의 값을 x0 레지스터가 가리키는 메모리에 저장. 단, ldaxr 명령과 이 명령 사이에 다른 CPU로부터 해당 메모리에 쓰기가 있는 경우 이 쓰기 처리는 실패
cbnz w9, .LBB0_1 ; if w9 != 0 goto .LBB0_1, w9 레지스터의 값을 검사해서 0이 아니면 다시 한 번 처리를 실행LL/SC 명령은 이렇게 다른 CPU로부터의 쓰기 여부를 검출할 수 있으며 이는 x86-64의 lock 명령 접두사와 크게 다른 점이다.
3.3 뮤텍스
뮤텍스(Mutex)는 MUTual EXecution의 약어이며 배타 실행(Exclusive Execution)이라고 불리는 동기 처리 방법이다. 이름 그대로 뮤텍스는 크리티컬 섹션을 실행할 수 있는 프로세스 수를 최대 1개로 제한하는 동기처리이다. 배타적 실행을 위해 공유 변수로 사용할 플래그를 준비하고 해당 플래그가 true이면 크리티컬 섹션을 실행하고 그렇지 않으면 실행하지 않는 처리를 생각할 수 있다. 이는 아래의 코드처럼 나타날 것이다.
bool lock = false; // 공유 변수 (1)
void some_func() {
retry:
if (!lock) {
lock = true; // 락 획득 (2)
// 크리티컬 섹션 (3)
} else {
goto retry;
}
lock = false;
}(1) 각 프로세스에서 공유되는 변수를 정의한다.
(2) 이미 다른 프로세스가 크리티컬 섹션을 실행 중이 아닌지 확인하고, 아무 프로세스도 실행하고 있지 않다면 크리티컬 섹션을 실행 중이라는 것을 나타내기 위해 공유 변수 lock에 true를 대입하고 크리티컬 섹션을 실행한다. 반대로 만약 다른 크리티컬 섹션을 실행 중인 프로세스가 있다면 재시도 한다.
(3) 공유 변수 lock에 false를 대입하고 처리를 종료한다.
이 함수는 여러 프로세스에서 동시에 호출되며, lock 변수는 모든 프로세스에서 공유된다. 이 프로그램은 얼핏 잘 작동할 것처럼 보이지만 여러 프로세스가 크리티컬 섹션을 동시에 실행하게 될 가능성이 있다. 아래의 그림을 한 번 살펴보자.

그림에서는 2개의 프로세스 A와 B가 공유 변수 lock에 접근한다. 프로세스 A가 some_func 함수 안에 있는 if의 조건 부분을 실행한 직후 프로세스 B가 마찬가지로 if의 조건 부분을 실행한다. 프로세스 B에 의한 lock 변수의 읽기는 프로세스 A가 lock 변수에 true를 설정한 것 보다 먼저 실행되므로 결과적으로 프로세스 A와 B 모두 같은 시각에 크리티컬 섹션을 실행하게 된다.
다음 코드는 올바른 배타 제어를 수행하는 구현 예다.
bool lock = false; // 공유 변수
void some_func() {
retry:
if (!test_and_set(&lock)) { // 검사 및 락 획득
// 크리티컬 섹션
} else {
goto retry;
}
tas_release(&lock); // 락 해제(반환)
}이 코드에서는 단순히 lock 변수를 검사해서 값을 설정하는 것 뿐만 아니라 아토믹 버전의 TAS 함수를 이용해 검사와 값 설정을 수행한다.
그러면 아래와 같이 올바르게 배타 실행이 이루어질 수 있다.
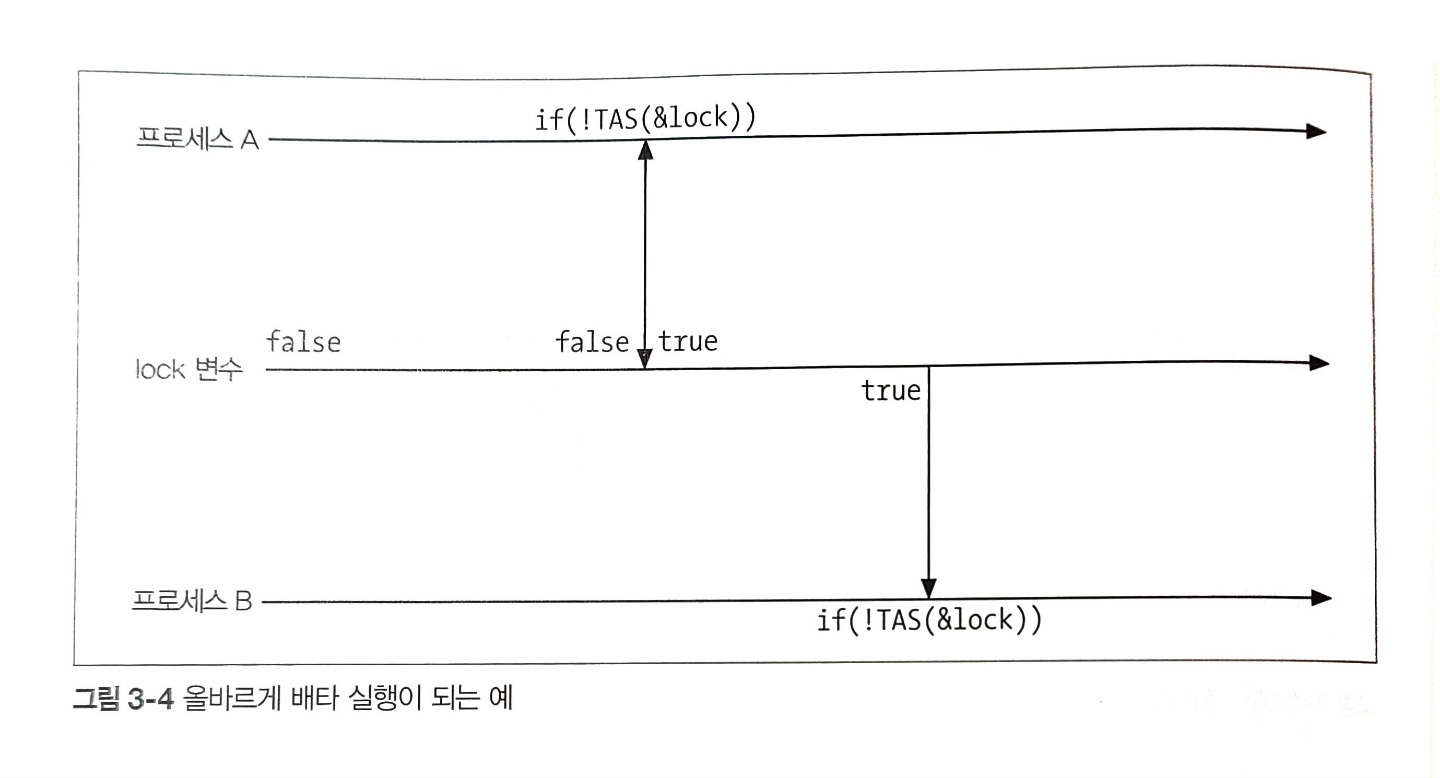
그림과 같이 TAS를 이용함으로써 lock 변수에 읽기와 쓰기를 동시에 수행할 수 있게 된다. 그리고 TAS에서 이용되는 xchg 명령은 캐시 라인을 배타적으로 설정하므로 같은 메모리에 대한 TAS는 동시에 실행되지 않는다.
3.3.1 스핀락
위의 예제에서는 락을 얻을 수 있을 때 까지 루프를 반복했다. 이렇게 리소스가 비는 것을 기다리며(polling) 확인하는 락 획득 방법을 스핀락(spinlock)이라고 한다. 전형적으로 스핀락용 API는 락 획득용과 락 해제용 함수 두 가지가 제공되며, 이들은 아래 코드와 같이 나타낼 수 있다.
void spinlock_acquire(bool *lock) {
while (test_and_set(lock)); // 공유 변수에 대한 포인터를 받아 TAS를 이용해 락을 획득할 때까지 루프를 돈다.
}
void spinlock_release(bool *lock) {
tas_release(lock); // 단순히 공유 변수를 인수로 tas_release 함수를 호출한다.
}코드는 정상 작동하지만 일반적으로 아토믹 명령은 실행 속도상 패널티가 크다. 그래서 TAS를 호출하기 전에 검사를 하고 나서 TAS를 수행하도록 개선할 수 있으며 개선한 결과는 다음 코드와 같다.
void spinlock_acquire(volatile bool *lock) {
for (;;) {
while(*lock); //
if (!test_and_set(lock))
break;
}
}
void spinlock_release(bool *lock) {
tas_release(lock);
} 스핀락에서는 락을 획득할 수 있을 때까지 루프에서 계속해서 공유 변수를 확인하기 때문에 크리티컬 섹션 안에서의 처리량이 많은 경우에는 불필요한 CPU 리소스를 소비하게 된다. 그래서 락을 획득하지 못한 경우에는 컨텍스트 스위치(context switch)로 다른 프로세스에 CPU 리소스를 명시적으로 전달해 계산 자원을 효율화하는 경우가 있다. 그리고 크리티컬 섹션 실행 중에 OS 스케줄러에 의해 OS 프로세스가 할당되어 대기 상태가 되어버린 경우에는 특히 패널티가 크다.
하지만 유저랜드 어플리케이션에서는 OS에 의한 할당을 제어하기 어렵기 때문에 단일 스핀락 이용은 권장하지 않으며 Pthread 또는 프로그래밍 언어 라이브러리가 제공하는 뮤텍스를 이용하거나 스핀락과 이들 라이브러리를 조합해 이용해야 한다.
스핀락을 사용한 예제 코드는 다음과 같다
bool lock = false;
void some_func() {
for (;;) {
spinlock_acquire(&lock); // 락 획득
// 크리티컬 섹션
spinlock_release(&lock); // 락 해제
}
}3.3.2 Pthreads의 뮤텍스
Pthreads의 뮤텍스에 대해 알아본다. 일반적인 프로그램의 경우 스핀락 등은 직접 구현하는 것보다 라이브러리에서 제공하는 뮤텍스를 이용하는 것이 바람직하다. 아래 코드는 Pthreads의 뮤텍스 이용 예시다.
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
pthread_mutex_t mut = PTHREAD_MUTEX_INITIALIZER; // 1
void* some_func(void *args) { // 스레드용 함수
if (pthread_mutex_lock(&mut) != 0) { // 2
perror("pthread_mutex_lock"); exit(-1);
}
// 크리티컬 섹션
if (pthread_mutex_unlock(&mut) != 0) { // 3
perror("pthread_mutex_unlock"); exit(-1);
}
return NULL;
}
int main(int argc, char *argv[]) {
// 스레드 생성
pthread_t th1, th2;
if (pthread_create(&th1, NULL, some_func, NULL) != 0) {
perror("pthread_create"); return -1;
}
if (pthread_create(&th2, NULL, some_func, NULL) != 0) {
perror("pthread_create"); return -1;
}
// 스레드 종료 대기
if (pthread_join(th1, NULL) != 0) {
perror("pthread_join"); return -1;
}
if (pthread_join(th2, NULL) != 0) {
perror("pthread_join"); return -1;
}
// 뮤텍스 객체 반환(릴리즈)
if (pthread_mutex_destroy(&mut) != 0) { // 4
perror("pthread_mutex_destroy"); return -1;
}
return 0;
}- 뮤텍스용 변수 mut를 정의한다. Pthreads에서는 뮤텍스용 공유 변수의 타입은 pthread_mutex_t이며 초기화는 PTHREAD_MUTEX_INITIALIZER 매크로에서 수행한다. 뮤텍스 초기화는 pthread_mutex_init 함수에서도 가능하다.
- pthread_mutex_lock 함수에 뮤텍스용 공유 변수 mut의 포인터를 전달해 락을 얻는다.
- pthread_mutex_unlock 함수에 mut으로 포인터를 전달하고 락을 해제한다. 이렇게 Pthreads 에서는 pthread_mutex_lock과 pthread_mutex_unlock 함수를 호출해 락 획득과 해제를 할 수 있다.
- 생성한 뮤텍스용 변수는 pthread_mutex_destroy 함수로 반환하지 않으면 메모리 누출을 일으킨다.
3.4. 세마포어
뮤텍스에서는 락을 최대 1개 프로세스까지 획득할 수 있었지만 세마포어(semaphore)를 이용하면 최대 N개의 프로세스까지 동시에 락을 획득할 수 있다. 여기서 N은 프로그램 실행 전에 임의로 결정할 수 있는 값이다.
즉, 세마포어는 뮤텍스를 보다 일반화한 것으로 또는 뮤텍스를 세마포어의 특수한 버전이라고 생각할 수 있다.
다음 코드는 세마포의 알고리즘을 나타낸다. 여기에서 NUM은 동시에 락을 획득할 수 있는 프로세스 수의 상한이다. 이 알고리즘에서는 int 타입의 공유 변수 cnt를 하나씩 이용하며 초깃값은 0이다.
#define NUM 4
void semaphore_acquire(volatile int *cnt) { // 1
for (;;) {
while (*cnt >= NUM); // 2
__sync_fetch_and_add(cnt, 1); // 3
if (*cnt <= NUM) // 4
break;
__sync_fetch_and_sub(cnt, 1); // 5
}
}
void semaphore_release(int *cnt) {
__sync_fetch_and_sub(cnt, 1); // 6
}
#include "semtest.c"- 인수로 int 타입의 공유 변수에 대한 포인터를 받는다. 뮤텍스의 경우 락이 이미 획득되어 있는지만 알면 되므로 bool 타입 공유 변수를 이용했지만 세마포어에서는 다수의 프로세스가 락을 획득했는지 알아야 하므로 int 타입을 이용한다.
- 공유 변수값이 최댓값 NUM 이상이면 스핀하며 대기한다.
- NUM 미만이면 공유 변수값을 아토믹하게 증가한다.
- 증가한 공유 변수값이 NUM 이하인지 검사하여 그렇다면 루프를 벗어나 락을 얻는다.
- 그렇지 않으면 여러 프로세스가 동시에 락을 획득한 것이므로 공유 변수값을 감소하고 다시 시도한다.
- 락을 반환한다. 공유 변수값을 아토믹하게 감소한다.
세마포어는 물리적인 계산 리소스 이용에 제한을 적용하고 싶은 경우 등에 이용할 수 있다. 그러나, 세마포어에서는 여러 프로세스가 락을 획득할 수 있으므로 뮤텍스에서는 피할 수 있었던 시뮬레이션을 피할 수 없는 경우가 많으므로 주의해야 한다.
3.4.1 LL/SC 명령을 이용한 구현
위에서 살펴본 예제에서는 락 획득을 실패한 경우 아토믹하게 공유 변수를 감소시켜야 했는데, 이는 락 획득시 값을 검사하지 않고 아토믹하게 증가시켰기 때문이다. 반면 LL/SC 명령을 이용하면 공유 변수를 검사해 필요한 경우에만 증가시키는 처리를 아토믹하게 수행할 수 있으므로 semaphore_acquire 함수 안에서 감소 처리할 필요가 없다.
3.4.2 POSIX 세마포어
여기에서 세마포어의 표준적인 구현인 POSIX 세마포어를 설명한다. 다음 코드는 POSIX 세마포어 이용 예이다.
#include <pthread.h> // 1
#include <fcntl.h>
#include <sys/stat.h>
#include <semaphore.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define NUM_THREADS 10 // 스레드 수
#define NUM_LOOP 10 // 스레드 안의 루프 수
int count = 0;
void *th(void *arg) { // 스레드용 함수
// 이름이 있는 세마포어를 연다. 3
sem_t *s = sem_open("/mysemaphore", 0);
if (s == SEM_FAILED) {
perror("sem_open");
exit(1);
}
for (int i = 0; i < NUM_LOOP; i++) {
// 4
if (see_wait(s) == -1) {
perror("sem_wait");
exit(1);
}
// 카운터를 아토믹하게 증가
__sync_fetch_and_add(&count, 1);
printf("count = %d\n", count);
// 10s 슬립
usleep(10000);
// 카운터를 아토믹하게 감소
__sync_fetch_and_sub(&count, 1);
// 세마포어 값을 증가시키고, 5
// 크리티컬 섹션에서 벗어난다.
if (sem_post(s) == -1) {
perror("sem_post");
exit(1);
}
}
// 세마포어를 닫는다. 6
if (sem_close(s) == -1)
perror("sem_close");
return NULL;
}
int main(int argc, char *argv[]) {
// 이름이 붙은 세마포어를 연다. 세마포어가 없을 때는 생성한다.
// 자신과 그룹이 이동할 수 있는 세마포어로
// 크리티컬 섹션에 들어갈 수 있는 프로세스는 최대 3개다. 7
sem_t *s = sem_open("/mysemaphore", 0_CREAT, 0660, 3);
if (s == SEM_FAILED) {
perror("sem_open");
return 1;
}
// 스레드 생성
pthread_t v[NUM_THREADS];
for (int i = 0; i < NUM_THREADS; i++) {
pthread_create(&v[i], NULL, th, NULL);
}
// join
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(v[i], NULL);
}
// 세마포어를 닫는다.
if (sem_close(s) == -1)
perror("sem_close");
// 세마포어 파기. 8
if (sem_unlink("/mysemaphore") == -1)
perror("sem_unlink");
return 0;
}- POSIX 세마포어는 Pthreads 라이브러리를 인클루드 하면 컴파일 및 실행 가능하다.
- 각 스레드 안에서 증감할 글로벌 변수 count를 정의한다.
- 스레드에서 이름이 붙은 세마포어를 생성한다.
- sem_wait 함수를 호출하고, 락을 획득할 때까지 대기한다.
- sem_post 함수를 호출하고, 세마포어의 값을 증가시켜 크리티컬 섹션을 벗어난다.
- 필요 없어진 세마포어는 sem_close 함수를 호출해서 닫아야 한다.
- main 함수 안에서 이름이 붙은 세마포어를 생성한다. 여기서는 0_CREAT를 지정했으므로 이미 해당 이름의 세마포어가 존재할 때는 생성하지 않고 열기만 한다. 세 번째 인수인 0660은 권한을 의미하며 이는 유닉스 계열 OS의 파일 권한과 동일하다. 여기에서는 OS 프로세스의 소유자와 그룹이 읽고 쓸 수 있도록 저장한다. 네 번째 인수인 3은 락을 동시에 획득할 수 있는 프로세스의 상한이다.
- 이름이 있는 세마포어를 닫은 것은 핸들러를 닫은 것뿐이므로 OS 측에는 세마포어용 리소스가 남아있다. 이를 완전히 삭제하려면 sem_unlink 함수를 호출해야 한다.
POSIX 세마포어에는 이름 있는 세마포어와 이름 없는 세마포어가 있다. 이름 있는 세마포어는 슬래시로 시작해 널 문자열로 끝나는 문자열로 식별되며, 이 문자열은 OS 전체에 적용되는 식별자가 된다. 이름 있는 세마포를 열 때(또는 생성할 때)는 sem_open 함수를 이용하고, 기본 세마포어를 닫을 때는 첫 번째 인수에 이름을 지정하고, 두 번째 인수에 0을 지정한다.
이름 있는 세마포어는 예제와 같이 파일로 공유 리소스를 지정할 수 있으며, sem_open으로 생성과 열기, sem_close와 sem_unlink로 닫기와 파기를 수행한다. 그렇기 때문에 이름 있는 세마포어를 이용하면 메모리를 공유하지 않는 프로세스 사이에서도 편리하게 세마포어를 구현할 수 있다.
한편, 이름 없는 세마포어를 생성하면 공유 메모리 영역이 필요하며 공유 메모리 상에 sem_init으로 생성하고, sem_distroy로 파기한다.
참고자료
<동시성 프로그래밍(Concurrent Programming> 다카노 유키 저, 한빛미디어
'Computer Sci.' 카테고리의 다른 글
| [번역] 까다로운 버그에서 배운 9년간의 교훈 (0) | 2026.03.11 |
|---|---|
| [동시성 프로그래밍] Ch4. 동시성 프로그래밍 특유의 버그와 문제점 (0) | 2023.12.13 |
| [한.권.컴.구] Ch1. 컴퓨터 내부의 언어 체계 (1) | 2022.09.25 |
| [동시성 프로그래밍] Ch3. 동기 처리 1 (하) (1) | 2022.09.06 |
| [동시성 프로그래밍] Ch1. 동시성과 병렬성 (0) | 2022.06.06 |