

플랫폼마다 제공하는 코드 재사용 메커니즘은 제각각이지만, 연관된 코드를 모듈(module)로 묶는 방법은 모두 지원한다. 본인이 선택한 개발 플랫폼에서 모듈성과 그것을 구현한 수 많은 코드를 이해하는 것은 아키텍트에게 대단히 중요한 일이다. 우리가 아키텍처를 분석해야 할 (메트릭, 피트니스 함수, 시각화 등) 많은 도구가 이 모듈성에 기반하기 때문이다.
모듈성은 일종의 구성 원리(organizing principle)이다. 아키텍트가 대충 아무렇게나 조각들을 이어 붙여 시스템을 설계하면 무수한 난관에 봉착해 옴짝달싹 못 하는 시스템이 되어 버린다. 물리학에 비유 하자면, 소프트웨어 시스템은 엔트로피(entropy, 무질서)가 증가하는 방향으로 움직이는 복잡한 시스템을 모델링한다. 질서를 유지하려면 물리적 시스템에 에너지를 투입해야 하는데, 소프트웨어 시스템도 마찬가지이다. 아키텍트는 끊임없이 에너지를 소비해서 시스템을 구조적으로 탄탄하게 유지해야 한다.
3.1 정의
사전에서 모듈을 찾아보면, 복잡한 구조를 만드는데 쓰이는 각각의 표준화한 부품이나 독립적인 단위 라고 나온다. 우리는 모듈성을 이용해 객체 지향 언어의 클래스나 함수형 언어의 함수가 될 만한 서로 연관된 코드를 논리적으로 묶는다. 프로그래밍 언어는 대부분 (자바의 패키지, 닷넷의 네임스페이스처럼) 모듈성 메커니즘을 제공하며, 개발자는 보통 연관된 코드를 함께 묶는 수단으로 모듈을 사용한다. (ex. 자바 패키지 com.mycompany.customer에는 고객에 관한 것을 담는 식)
아키텍트는 개발자가 코드를 어떻게 패키징하는지 반드시 알아야 한다. 아키텍처에 중요한 영향을 미치기 때문이다. 여러 패키지가 서로 단단히 커플링되어 있으면 그 중 하나를 다른 작업에 재사용하기가 아주 어려워진다.
클래스 이전 시절의 모듈 재사용
객체 지향 언어 이전 세대에는 각기 다른 많은 체계가 따로따로 존재하였는데 그 원인은 하위 호완성(backward compatibility)과 관련이 있다. 이는 코드의 하위호환성이 아니라, 개발자가 생각하는 방식에 관한 하위 호환성을 말한다.
1968년 에츠허르 다익스트라(Edsger Dijkstra)는 ACM 통신지에 이라는 논문을 발표했는데, 그는 당시 프로그래밍 언어에서 GOTO 문이 남용된 까닭에 코드 내에서 비선형적인 흐름이 잦아 로직을 이해하고 디버깅하기 너무 어려웠던 점을 지적했다.
이 논문은 파스칼(Pascal)과 C로 대표되는 구조적 프로그래밍 언어(structured programming language)의 시대를 이끌었고 코드를 서로 어떻게 연결하면 좋을지 깊이 생각해보는 계기가 되었다. 개발자들은 곧 대부분의 언어에서 코드를 논리적으로 함께 묶을 방법이 마땅치 않다는 사실을 깨달았다. 모듈성 언어가 잠시 인기를 끌기는 했지만, 오래 가지는 못했다.
대신 코드를 캡슐화 하여 재사용하는 새로운 지평을 연 객체 지향 언어가 인기를 끌었다. 그러나 모듈이 얼마나 유용한지 깨달은 언어 설계자들은 패키지, 네임 스페이스 같은 형태로 모듈을 존속시켰다.
우리는 아키텍처를 논할 때 클래스, 함수처럼 코드를 묶어 놓은 덩어리를 모듈성이라는 일반 용어로 나타낸다. 이것은 논리적인 구분이지 물리적인 구분은 아닌데, 이 차이점이 중요한 경우가 있다. 예컨데, 모놀리틱 어플리케이션은 편의상 꽤 많은 클래스를 한 덩이로 묶어도 크게 상관이 없지만, 아키텍처를 재구축할 때는 이렇게 커플링된 구조가 모놀리스를 나누는데 걸림돌이 된다. 따라서 모듈성은 특정 플랫폼에 함축되어 있거나 불가피한 물리적인 분리와 다른 개념으로 바라보는 것이 좋다.
닷넷 플랫폼에는 기술 구현과 분리된 네임스페이스(namespace)라는 일반적인 개념이 있다. 개발자는 상이한 (컴포넌트, 클래스 등의) 소프트웨어 자산을 서로 구분하기 위해 정확한 완전 정규화 명칭(Fully Qualified Name, FQN)을 필요로 한다. 인터넷을 예로 들면, 인터넷에는 IP 주소와 매핑된 고유한 글로벌 식별자가 있다. 대부분의 언어에도 변수, 함수, 메서드 등을 구성하는 데 필요한 네임스페이스 역할을 하는 모듈성 메커니즘이 있다.
3.2 모듈성 측정
3.2.1 응집
응집(cohesion)은 한 모듈은 파트가 동일한 모듈 안에 얼마나 포함되어 있는지를 나타낸다. 다시 말해, 모듈을 구성하는 파트가 서로 얼마나 연관되어 있는가, 하는 것이다. 이상적으로 응집된 모듈이라면 모든 파트가 함께 패키징 되어 있다. 파트를 더 잘게 쪼개려면 모듈 간 호출을 통해 파트를 묶어야 유용한 결과를 얻을 수 있기 때문이다.
응집된 모듈을 나누려고 해봐야 더 커플링되고 가독성은 떨어진다. - 래리 콘스탄틴(Larry Constantine)
컴퓨터 과학자들은 응집도의 측정 범위를 정의했는데, 좋은 것부터 나쁜 것 순으로 나열해 본다.
- 기능적 응집 (functional cohesion) : 모듈의 각 파트는 다른 파트와 연관되어 있고, 기능상 꼭 필요한 모든 것이 모듈에 들어있다.
- 순차적 응집 (sequential cohesion) : 두 모듈이, 한쪽이 데이터를 출력하면 다른 한 쪽이 그것을 입력받는 형태로 상호작용한다.
- 소통적 응집 (communication cohesion) : 두 모듈이, 각자 정보에 따라 작동하고(거나) 어떤 출력을 내는 형태로 통신 체인(communication chain)을 형성한다. 예를 들면, 데이터베이스에 레코드를 추가하면 그 정보에 따라 이메일이 만들어지는 식이다.
- 절차적 응집 (procedural cohesion) : 두 모듈은 정해진 순서대로 실행되어야 한다.
- 일시적 응집 (temporal cohesion) : 모듈은 시점 의존성(timing dependency)에 따라 연관된다. 예를 들어, 많은 시스템들이 시동할 때 그다지 관련이 없어 보이는 것들을 죽 초기화하는 경우가 많은데, 이런 작업들이 일시적으로 응집되었다고 할 수 있다.
- 논리적 응집 (logical cohesion) : 모듈의 내부 데이터는 기능적이 아니라 논리적으로 연관되어 있다. 이를테면, 텍스트, 직렬화 객체, 스트림 형태로 받은 데이터를 변환하는 모듈이 그렇다. 서로 연관된 작업들이지만 하는 일은 전혀 다르다. 이런 종류의 응집의 좋은 예는 거의 모든 자바 프로젝트에서 사용되는 StringUtils 패키지에서 찾아볼 수 있다. 이 패키지에는 각기 다른 작업을 수행하는 정적 메서드가 많이 있지만 서로 연관성은 없다.
- 동시성 응집 (coincidental cohesion) : 같은 소스 파일에 모듈 구성 요소가 들어 있지만, 그 외에는 아무 연관성도 없다. 이는 가장 좋지 않은 형태의 응집이다.
컴퓨터 과학자들은 응집의 주관성(subjectiveness)을 전제로, 응집도(좀 더 구체적으로는 응집의 결여도)를 가능할 수 있는 정말 우수한 구조적 메트릭을 개발했다. 카이댐버와 케메러가 개발한 ‘메서드의 응집 결여도(Lack Of Cohesion in Methods, LCOM)는 모듈(보통 컴포넌트)의 구조적 응집도를 나타낸다. 처음 계산 공식은 다음과 같다.
$$
LCOM =
\begin{cases}
|P|-|Q|, & if|P|>|Q| \
0, & else
\end{cases}
$$
위 식에서 P는 특정 공유 필드에 엑세스 하지 않는 메서드 수만큼 증가하고, 반대로 Q는 특정 공유 필드를 공유하는 메서드 수만큼 감소한다. 이 식은 점점 정교하게 다듬어져 1996년 LCOM96b라는 두 번째 버전이 등장했다.
$$
LCOM96b = { 1\over a}\sum_{j=1}^a {m-\mu(Aj)\over m}
$$
기본적으로 LCOM 메트릭은 클래스 내부의 부차적인 커플링을 나타내는데, 다음과 같이 정의하면 좀 더 이해하기 쉽다.
LCOM : 공유 필드를 통해 공유되지 않는 메서드의 총 갯수
예를 들어, 프라이빗 필드 a,b가 있는 클래스가 있다고 가정하자. 이 클래스에는 a만 액세스하는 메서드가 있고, b만 액세스 하는 메서드도 있다. 공유 필드 (a와 b)를 통해 공유되지 않는 메서드는 많기 때문에 이 클래스의 LCOM 점수는 높다. 즉, 메서드의 응집 결여도가 높은 것이다. 아래 그림에 세 클래스를 보자.

클래스 X는 LCOM 점수가 낮고 구조적 응집이 우수한 반면, 클래스 Y는 응집이 결여되어 있습니다. 클래스 Y의 필드/메서드 세 쌍은 각자 자기 클래스에 두어도 별로 상관이 없을 듯 하다. 클래스 Z는 응집이 조합된 모양새로, 세 번째 필드/메서드 쌍은 개발자가 자체 클래스로 빼내도 된다.
LCOM 메트릭은 아키텍처 스타일을 전환하기 위해 코드베이스를 분석하는 아키텍트에게 매우 유용하다. 아키텍처 전환 시 가장 골치 아픈 문제 중 하나가 바로 공유 유틸리티 클래스이다. LCOM 메트릭을 활용하면 어쩔 수 없이 커플링된 클래스, 처음부터 한 클래스가 아니었던 클래스를 발견하는데 도움이 된다.
3.2.2. 커플링(결합도, 의존도)
코드 베이스의 커플링은 그래프 이론에 기반한 좋은 분석 도구들이 많이 있다. 메서드의 호출과 반환은 호출 그래프를 형성하므로 수학적인 분석이 가능하다. 1979년 에드워드 요던(Edward Yourdon)과 래리 콘스탄틴(Larry Constantine)이 지은 에는 구심(afferent) 커플링, 원심(efferent) 커플링을 비롯한 중요한 개념들이 대거 등장한다. 구심 커플링은 (컴포넌트, 클래스, 함수 등의) 코드 아티팩트로 유입된는 접속 수를, 원심 커플링은 다른 코드 아티팩트로 유출되는 접속 수를 나타낸다. 어느 플랫폼이든 아키텍트가 코드 베이스를 재구성, 마이그레이션, 분석할 때 도움을 주는 커플링 특성 분석 도구는 거의 다 있다.
3.2.3 추상도, 불안정도, 메인 시퀀스로부터의 거리
추상도(abstractness)는 (추상 클래스, 인터페이스 등의) 추상 아티팩트(abstract artifact)와 구상 아티팩트(concrete artifact, 구현체)의 비율, 즉 구현 대비 추상화 정도를 나타낸다. 아래 식은 추상도를 구하는 공식이다.
$$
A = {\Sigma m^a \over \Sigma m^c}
$$
( $m^a$는 모듈에 있는 추상(abstract) 요소(인터페이스 또는 추상 클래스), $m^c$는 구상(concrete) 요소(비 추상 클래스) )
예컨데, 5000라인에 달하는 코드를 전부 main() 메서드에 구현한 어플리케이션이 있다면 위의 식에서 분자는 1, 분모는 5000 이므로 추상도는 0에 가깝다. 즉, 추상도는 우리가 작성한 코드의 추상화율을 수치화한 메트릭이다.
아키텍트는 추상 아티팩트의 총 개수와 구상 아티팩트의 총 갯수로 추상도를 계산한다.
여기서 파생된 불안정도(instability)는 원심 커플링(구심 커플링 + 원심 커플링)의 비율이다.
$$
I = {{C^e} \over {C^e + C^a}}
$$
( $C^e$는 원심(나가는) 커플링, $C^a$는 구심(들어오는) 커플링 )
불안정도는 코드 베이스의 변동성(volatility)을 의미하므로 불안정도가 높은 코드베이스는 변경 시 커플링이 높아 더 깨지기 쉽다. 예를 들어 여러 다른 클래스를 호출해서 작업을 위임하는 클래스는 호출되는 메서드 중 하나라도 변경되면 호출하는 이 클래스 역시 잘못될 공산이 매우 크다.
3.2.4 메인 시퀀스로부터의 거리
메인 시퀀스로부터의 거리는 아키텍처 구조를 평가하는 몇 가지 전체적인 메트릭 중 하나로, 불안정도와 추상도를 이용하여 계산한다.
$$
D = |A+I-1|
$$
( A는 추상도, I는 불안정도 )
메인 시퀀스로부터의 거리는 추상도와 불안정도 사이의 이상적인 관계를 나타낸다. 예를 들어 아래의 그래프에서 클래스의 메인 시퀀스로부터의 거리는 D이다.

위의 그래프에서 개발자는 후보 클래스를 그려보고 이상적인 선에서 얼마나 떨어져 있는지 거리를 잰다. 이 선에 가까울 수록 클래스 균형이 잘 맞다는 방증이다. 오른쪽 위로 치우친 부분을 쓸모없는 구역(zone of uselessness, 너무 추상화를 많이 해서 사용하기 어려운 코드), 반대로 왼쪽 아래로 치우친 부분을 고통스런 구역(zone of pain, 추상화를 거의 안 하고 구현 코드만 잔뜩 넣어 취약하고 관리하기 힘든 코드)이라고 한다.

3.2.5 커네이선스
밀러 페이지-존스 Meilir Page-Jones는 1996년 출간된 <What Every Programmer Should Know About Object-Oriented Design)에서 구심/원심 커플링 메트릭을 더욱 발전시킨 커네이선스(connascence) 개념을 객체 지향 언어의 화두로 던졌다.
두 컴포넌트 중 한 쪽이 변경될 경우 다른 쪽도 변경해야 전체 시스템의 정합성이 맞는다면 이들은 커네이선스를 갖고 있는 것이다. - 밀러 페이지 존스
그는 커네이선스를 정적 커네이선스와 동적 커네이선스로 분류했다.
- 정적 커네이선스 : (실행 시간 커플링과 정반대인) 소스 코드 레벨의 커플링으로, (Prentice-Hall, 1979)에서 등장하는 구심/원심 커플링을 발전시킨 개념이다. 다시 말해, 아키텍트는 구심적이든, 원심적이든 다음 종류의 정적 커네이선스를 뭔가에 커플링된 정도라고 보는 것이다.
- 동적 커네이선스 : 런타임 호출을 분석하는, 페이지-존스가 정의한 또 다른 유형의 커네이선스이다.
커네이선스는 아키텍트와 개발자에게 유용한 분석 도구이다. 다음 속성들을 잘 활용하면 개발자에게 큰 도움이 된다.
- 강도 : 아키텍트는 개발자가 어떤 유형의 커네이선스를 얼마나 쉽게 리팩터링 할 수 있는지에 따라 커네이선스 강도(strength)를 결정한다. 아래 그림처럼, 다양한 유형의 커네이선스가 더 바람직하다. 아키텍트와 개발자는 더 나은 유형의 커네이선스를 리팩터링해서 코드베이스의 커필링 특성을 개선할 수 있다.
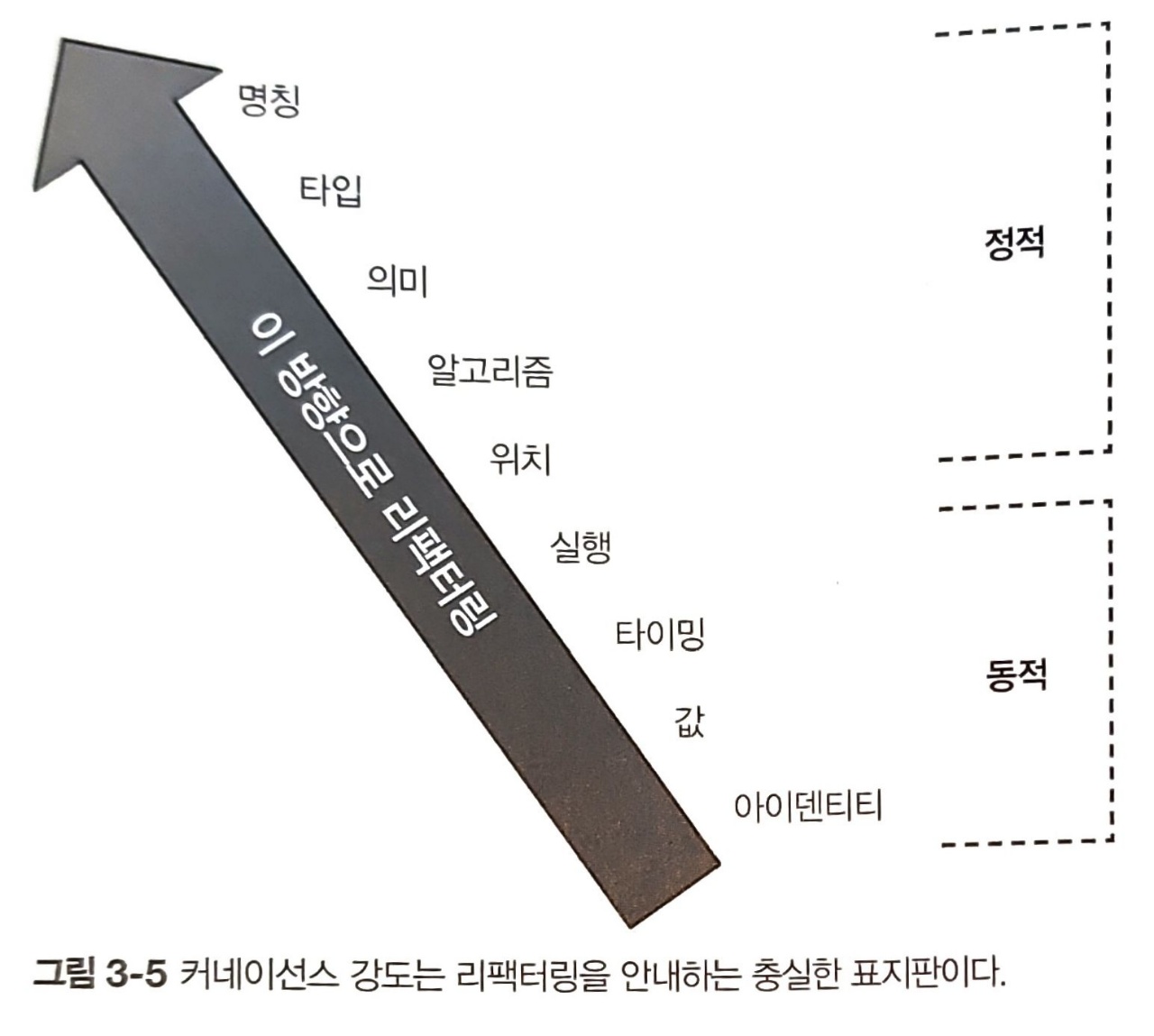
- 지역성 : 커네이선스의 지역성(locality)은 코드베이스의 모듈들이 서로 얼마나 가까이 있는가 이다. (동일한 모듈에서) 근접한 코드는 보통 (별개의 모듈 또는 코드베이스로) 더 분리된 코드보다 높은 형태의 커네이선스를 가진다. 즉, 모듈을 서로 떨어뜨렸을 때 커플링이 형편없는 형태의 커네이선스는 모듈을 서로 가까이 붙여 놓는 식으로 개선할 수 있다. 만약, 동일한 컴포넌트에 있는 두 클래스가 의미 커네이선스를 갖고 있다면, 두 컴포넌트가 동일한 형태의 커네이선스를 갖고 있을 때보다 코드베이스에 덜 해로울 것이다.
- 정도 : 커네이선스 정도(degree)는 커네이선스가 미치는 영향의 규모(소수의 클래스에 영향을 미치는가, 아니면 수 많은 클래스에 영향을 미치는가)에 관한 것이다. 이 값이 작을수록 코드베이스 입장에서 바람직하다. 다음은 페이지-존스가 제시한, 커네이선스를 이용해 시스템의 모듈성을 개선하는 세 가지 방법이다.
- 시스템을 캡슐화한 요소들로 잘게 나누어 전체 커네이선스를 최소화한다.
- 캡슐화 경계를 벗어나는 나머지 커네이선스를 모조리 최소화한다.
- 캡슐화 경계 내부에서 커네이선스를 최대화한다.
3.3 모듈에서 컴포넌트로
이 책에서는 연관된 코드의 묶음을 모듈(module)이라는 일반적인 용어로 표현하지만, 대부분의 플랫폼은 소프트웨어 아키텍트에게 핵심 구성 요소 중 하나인 컴포넌트(components)형태로 지원한다. 문제 영역에서 컴포넌트를 도출하는 방법은 이후에 다룰 예정이다.
참고자료
<소프트웨어 아키텍처 101>, 마크 리처즈, 닐 포드 저, 한빛미디어
'Computer Sci. > SW Architecture' 카테고리의 다른 글
| [소프트웨어 아키텍처 101] Ch06. 아키텍처 특성 측정 및 거버넌스 (1) | 2022.05.02 |
|---|---|
| [소프트웨어 아키텍처 101] Ch04~05. 아키텍처 특성 정의, 식별 (0) | 2022.04.14 |
| [소프트웨어 아키텍처 101] Ch02. 아키텍처 사고 (0) | 2022.02.02 |
| [소프트웨어 아키텍처 101] Ch01. 서론 (0) | 2022.01.21 |